A method for applying standardized, customizable "similar soils" rules to arbitrary site-level data.
Usage
similar_soils(
x,
mapping,
condition = NULL,
idname = "id",
thresh = NULL,
thresh_single = 2,
thresh_all = 3,
absolute = TRUE,
verbose = TRUE
)Arguments
- x
A data.frame or a SoilProfileCollection.
- mapping
named list of functions. List element names refer to site-level data columns of
x. Each function performs a conversion of the raw data inxto a value used in the "similar soils" distance calculation.- condition
integer or character. For default (
NULL) the value is calculated internally based on the dominant condition of intersection of mapping results inx. You may specify an integer row ID inxfor specific similar soil contrasts, or you can specify a character dominant condition equivalent to the name assigned byinteraction()e.g."4.3"for a two rating mapping result where the first rating has value4and the second has value3.- idname
character. ID column name, default
"id".- thresh
integer. Deprecated. If used, the same value is passed to
thresh_allandthresh_single.- thresh_single
integer. hreshold difference in any one property required to be dissimilar. Default
2. See details for discussion on the default calculation for similarity.- thresh_all
integer. Threshold sum of differences across all properties required to be dissimilar. Default
3. See details for discussion on the default calculation for similarity.- absolute
logical. Report absolute difference? Default:
TRUE. Absolute difference is always used for comparison againstthresh_singleandthresh_all, but the sign of the difference can be relevant to interpretation of relative limitations of soils.- verbose
Default:
TRUEmessage about selectedcondition.
Value
A data.frame containing inputs and three new columns:
similar_single (maximum difference in any one property, relative to
condition), similar_dist (cumulative sum of differences relative to
condition), similar (logical; soil is similar to condition)
Details
The sum of differences across conditions (specified by the intersection of
output of the functions in mapping) is used as the "distance" of a soil
relative to condition. A threshold value is used to decide which are
"similar" and which are not. The functions in mapping can be customized
to use alternate thresholds: thresh_single defines the maximum distance
in any one property for soils considered to be similar, whereas thresh_all
defines the maximum sum of distances across all properties. Defaults reflect
thresholds used by Norfleet and Eppinette (1993) and replicated in most
local similarity guides.
References
Norfleet, M.L. and Eppinette, R.T. (1993), A Mathematical Model for Determining Similar and Contrasting Inclusions for Map Unit Descriptions. Soil Survey Horizons, 34: 4-5. https://doi.org/10.2136/sh1993.1.0004
Examples
data(loamy, package = "SOILmilaR")
rate_taxpartsize <- function(x) {
dplyr::case_match(x,
c("sandy-skeletal") ~ 1,
c("sandy") ~ 3,
c("loamy", "coarse-loamy", "coarse-silty") ~ 5,
c("fine-loamy", "fine-silty") ~ 7,
c("clayey", "fine") ~ 9,
c("very-fine") ~ 11,
c("loamy-skeletal", "clayey-skeletal") ~ 13,
"fragmental" ~ 15)
}
rate_depthclass <- function(x, breaks = c( `very shallow` = 25, `shallow` =
50, `moderately deep` = 100, `deep` = 150, `very deep` = 1e4 ), pattern =
"R|Cr|Cd|kk|m", hzdesgn = aqp::guessHzDesgnName(x, required = TRUE),
...) {
res <- cut(x, c(0, breaks))
factor(res, levels = levels(res), labels = names(breaks), ordered = TRUE)
}
rate_pscs_clay <- function(x,
breaks = c(18, 27, 40, 60, 100)) {
res <- cut(x, c(0, breaks))
factor(res, levels = levels(res), ordered = TRUE)
}
m <- list(taxpartsize = rate_taxpartsize, depth = rate_depthclass,
pscs_clay = rate_pscs_clay)
s <- similar_soils(loamy, m)
#> comparing to dominant reference condition (`13.moderately deep.(0,18]` on 5 rows)
head(s)
#> id taxpartsize depth pscs_clay similar_dist similar_single
#> 1 A1 7 moderately deep (27,40] 8 6
#> 2 B1 7 deep (18,27] 8 6
#> 3 C1 7 moderately deep (27,40] 8 6
#> 4 D1 7 deep (27,40] 9 6
#> 5 E1 5 deep (0,18] 9 8
#> 6 F1 5 shallow (0,18] 9 8
#> group similar
#> 1 7.moderately deep.(27,40] FALSE
#> 2 7.deep.(18,27] FALSE
#> 3 7.moderately deep.(27,40] FALSE
#> 4 7.deep.(27,40] FALSE
#> 5 5.deep.(0,18] FALSE
#> 6 5.shallow.(0,18] FALSE
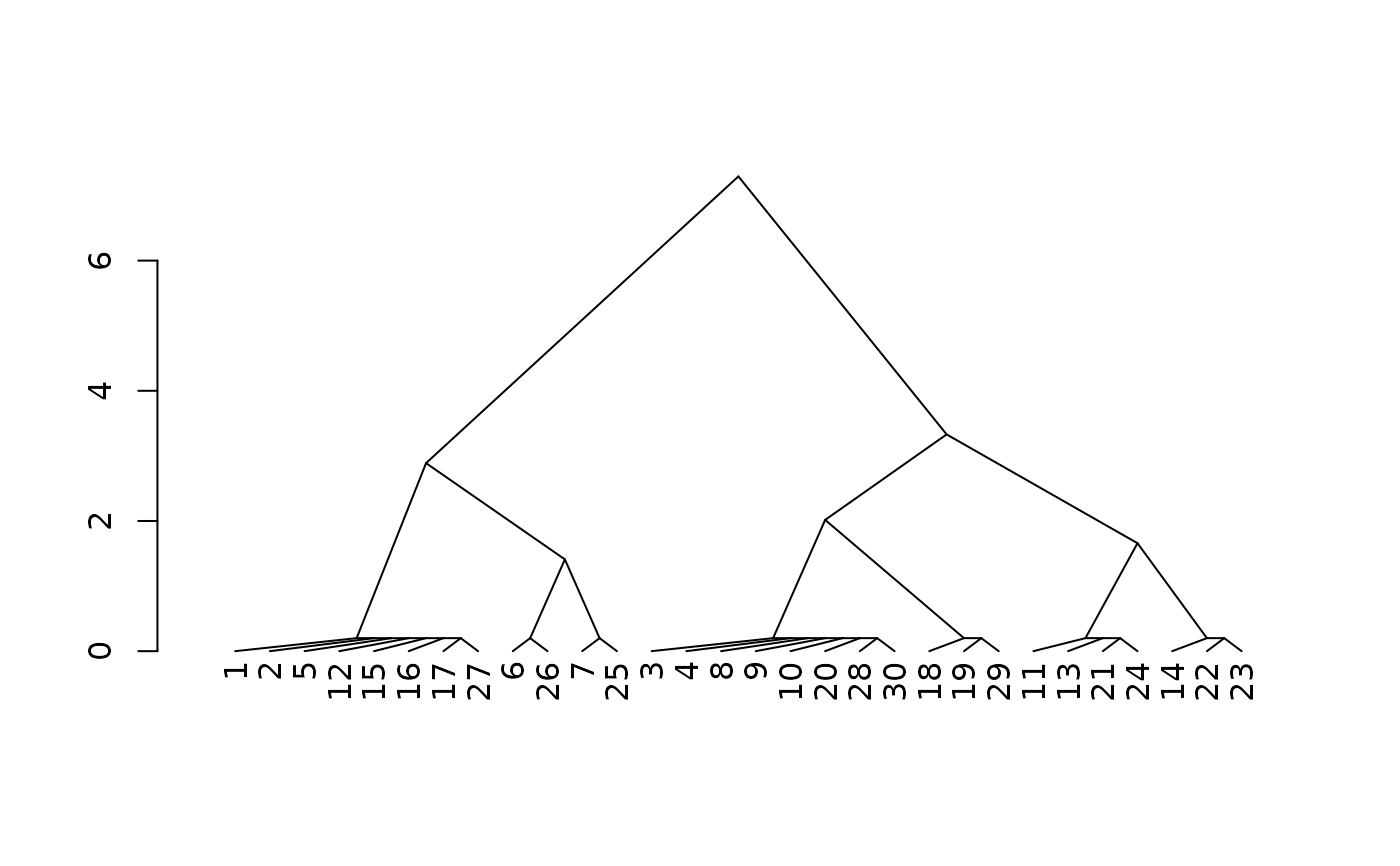
# inspect distances using agglomerative clustering+dendrogram
d <- cluster::agnes(s[, 5, drop = FALSE], method="gaverage")
d$height <- d$height + 0.2 # fudge factor for 0-distance
plot(stats::as.dendrogram(d), center=TRUE, type="triangle")
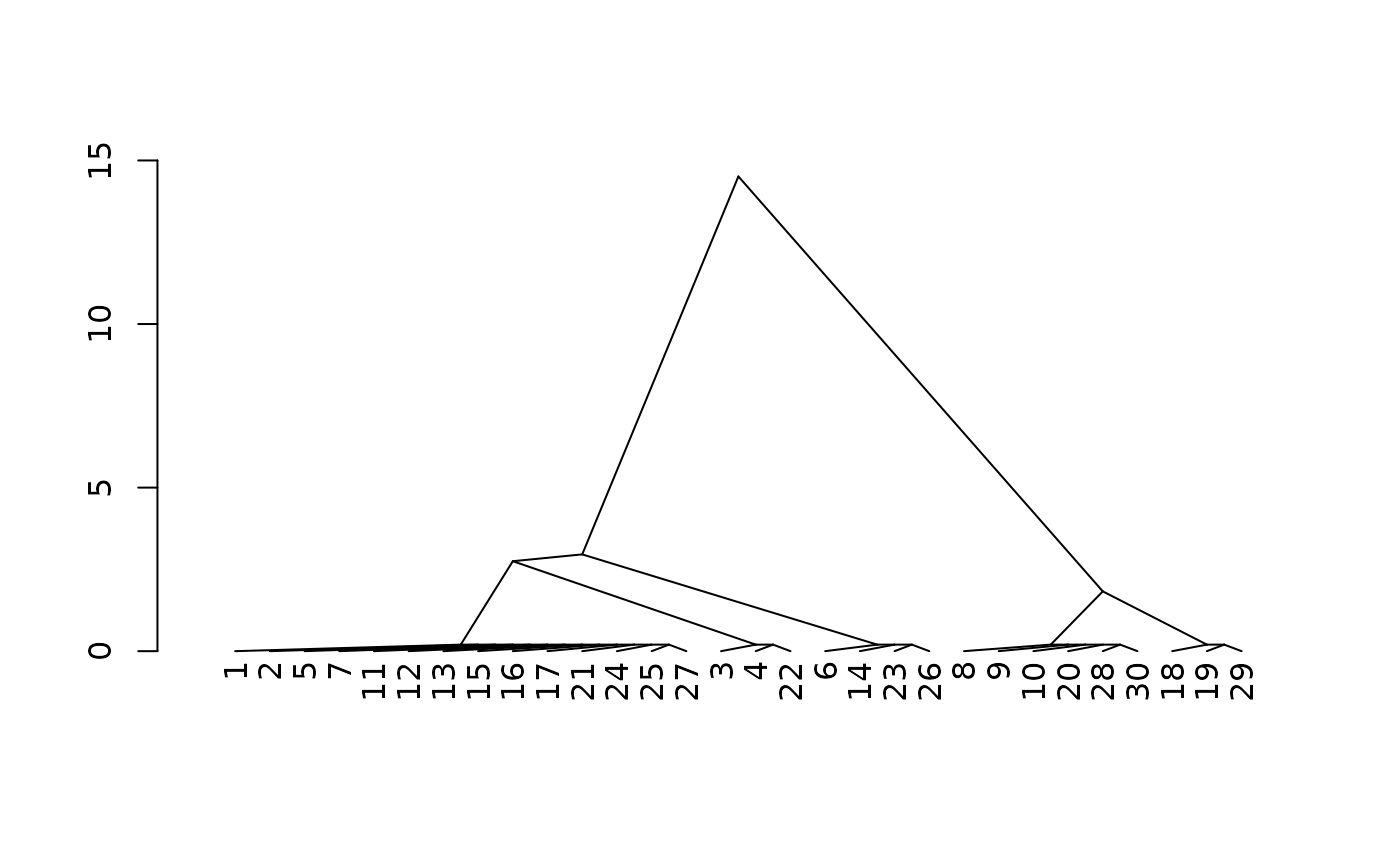 # allow relative contrast ratings to be negative # (i.e. ordinal factors, concept of "limiting")
# absolute value is still used for "similar" threshold
s2 <- similar_soils(loamy, m, absolute=FALSE)
#> comparing to dominant reference condition (`13.moderately deep.(0,18]` on 5 rows)
# inspect distances using agglomerative clustering+dendrogram
d2 <- cluster::agnes(s2[, 5, drop = FALSE], method="gaverage")
d2$height <- d2$height + 0.2 # fudge factor for 0-distance
plot(stats::as.dendrogram(d2), center=TRUE, type="triangle")
# allow relative contrast ratings to be negative # (i.e. ordinal factors, concept of "limiting")
# absolute value is still used for "similar" threshold
s2 <- similar_soils(loamy, m, absolute=FALSE)
#> comparing to dominant reference condition (`13.moderately deep.(0,18]` on 5 rows)
# inspect distances using agglomerative clustering+dendrogram
d2 <- cluster::agnes(s2[, 5, drop = FALSE], method="gaverage")
d2$height <- d2$height + 0.2 # fudge factor for 0-distance
plot(stats::as.dendrogram(d2), center=TRUE, type="triangle")